Fundamental Types
- Describe the fundamental types of C++
- Describe the syntax for constants for each type
"Define types appropriately, then read and write data using those types instead of thinking bits and words and addresses." Sutter, Alexandrescu (2005)
Any type relates an object in a program to its underlying implementation in hardware. A programming language's type system distinguishes the regions of memory accessible by the program from one another. The type assigned to a region of memory identifies the nature of the information stored in that region. That information may be value data, address data, or program instructions.
The type of any region of memory defines two distinct aspects of the object stored in that memory:
- how to interpret the bit string in the region of memory
- the operations that are admissible on the bit string in that region of memory
Each fundamental type defined in the C++ core language consists of an integral number of bytes (1, 2, etc.).
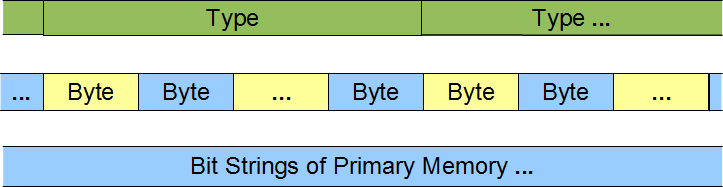
This chapter describes the fundamental types in C++. These fundamental types include integer types and floating-point types. The integer types include the character types for representing the different language symbols in the world. This chapter also describes the syntax for initialization, type inference from previously declared types and the alignment of types in memory.
Integer Types
The integer types consist of:
- standard integers; either
- signed standard integers, or
- unsigned standard integers
- booleans
- character types
Range specifiers on the standard integer types set the ranges of values associated with these types. They are:
signed- negative and positive valuesunsigned- no negative values
Integer types represent their values using the binary numeration system. The ordering of the bytes within any multi-byte type is platform-implemented. Big-endian platforms store the highest order byte first, while little-endian platforms store the lowest order byte first. Some PowerPC platforms can switch modes; Intel platforms (x86) are typically little-endian. The ordering of bits within each byte is also platform dependent. These finer details are unspecified by the C++ language standard.
Standard Signed Integers
C++17 defines five signed standard integer types:
signed charshort intintlong intlong long int
A signed standard integer type can hold negative and positive values. The leading word, if any, before int is its size specifier. A short int fits between a signed char and an int, an int fits between a short int and a long int, and a long int fits between an int and a long long int.
signed char
A signed char occupies enough bits (typically, one byte) to store the language's basic character set:

We use a signed char type to read character input from a file and trap the end of file mark (EOF, which typically has a value of -1).
signed char c; // for possibility of receiving EOF
We define a constant of signed char type using single quotes around the value and can express it in character, octal, or hexadecimal notation:
signed char k, m, n, p;
k = '['; // character
m = '\133'; // octal - note the leading \
n = '\x5b'; // hexadecimal - note the leading \x
p = '\X5B'; // hexadecimal - note the leading \X
The single quotes identify a character literal. The host platform converts the enclosed characters to a decimal value based on the platform's encoding sequence.
short int
A short int, or simply a short, occupies at least as much memory as a signed char (typically, at least 16 bits):
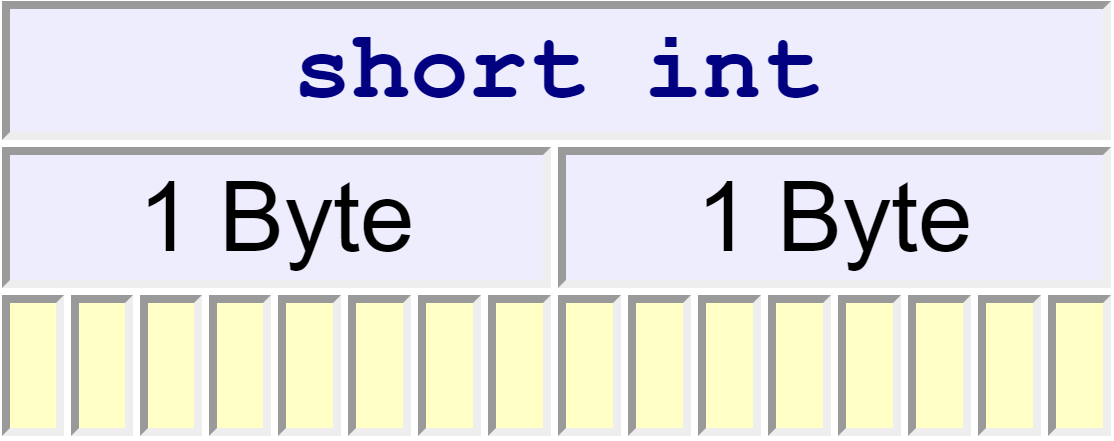
C++ does not support syntax for constant literals of short int type (i.e., integer literals on 2 bytes).
int
An int occupies at least as much memory as a short int (typically, 32 bits):

We define a constant of int type using decimal, octal, or hexadecimal notation:
int a, b, c, d;
a = 91; // decimal
b = 0133; // octal - note the leading 0
c = 0x5b; // hexadecimal - note the leading 0x
d = 0X5B; // hexadecimal - note the leading 0X
long int
A long int, or more concisely a long, occupies at least as much memory as an int (typically, 32 bits):

We define a constant of long int type using decimal, octal, or hexadecimal notation with the suffix L or l:
long int a, b, c, d;
a = 91L; // decimal notation
b = 0133L; // octal notation; note the leading 0
c = 0x5bL; // hexadecimal notation; note the leading 0x
d = 0X5BL; // hexadecimal notation; not the leading 0X
long long int
A long long int, or more concisely a long long, occupies at least as much memory as a long int (typically, 64 bits):

We define a constant of long long int type using decimal, octal, or hexadecimal notation with the suffix LL or ll:
long long int a, b, c, d;
a = 91LL; // decimal
b = 0133LL; // octal
c = 0x5bLL; // hexadecimal
d = 0X5BLL; // hexadecimal
Ranges
The finite number of bytes in any standard integer type limits the number of different values that the type can hold. The range of values for a signed standard integer type depends on the encoding scheme for negative values. Encoding schemes for negative values include:
- two's complement - flip the bits and subtract one
- one's complement - flip the bits
- sign magnitude - reserve one bit for the sign
All three schemes represent positive values identically. Two's complement, which is the most popular, renders separate ALU subtraction circuits redundant and yields only one representation of 0.
For a two's complement encoding scheme, typical ranges are:
| Type | Min | Max |
|---|---|---|
signed char | -128 | 127 |
short int | <= -32,768 | >= 32,767 |
int | -2,147,483,648 | 2,147,483,647 |
long int | <= -2,147,483,648 | >= 2,147,483,647 |
long long int | <= -9,223,372,036,854,775,808 | >= 9,223,372,036,854,775,807 |
Unsigned Standard Integers
The five unsigned types, which correspond to the signed standard integer types, are
unsigned charunsigned short intunsigned intunsigned long intunsigned long long int
We use unsigned types for variables that only hold non-negative values. For example:
unsigned char letter;unsigned short int languages;unsigned int persons;unsigned long int students;unsigned long long int citizens;
We define an unsigned constant using decimal, octal, or hexadecimal notation with the suffix U or u:
unsigned int g;
unsigned long int h;
unsigned long long int k;
g = 0x5bU; // unsigned int: U or u
h = 0X5BUL; // unsigned long: (U or u) and (L or l) any order
k = 456789012345ULL; // unsigned long long: (U or u, LL or ll) any order
An unsigned type occupies the same amount of memory as its signed counterpart.
Ranges
Typical ranges for the unsigned standard integer types are:
| Type | Min | Max |
|---|---|---|
usigned char | 0 | 255 |
unsigned short int | 0 | >=65,535 |
unsigned int | 0 | 4,294,967,295 |
unsigned long int | 0 | >= 4,294,967,295 |
unsigned long long int | 0 | >= 18,446,744,073,709,551,615 |
Comparing the values in this table to those in the table for a signed standard integer type shows that those values are a subset of those for the corresponding unsigned type.
bool Type
The bool type typically occupies one byte:
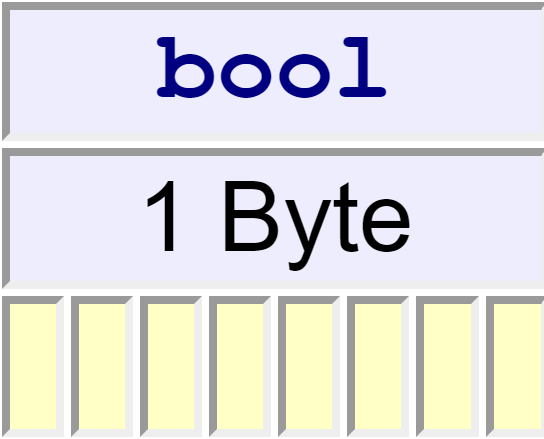
A variable of bool type can hold one of two values:
falsetrue
Character Types
C++17 defines six character types:
charsigned charunsigned charwchar_tchar16_tchar32_t
signed char, unsigned char, char
The first three char types occupy the same amount of memory - enough to hold the implementation's basic character set:
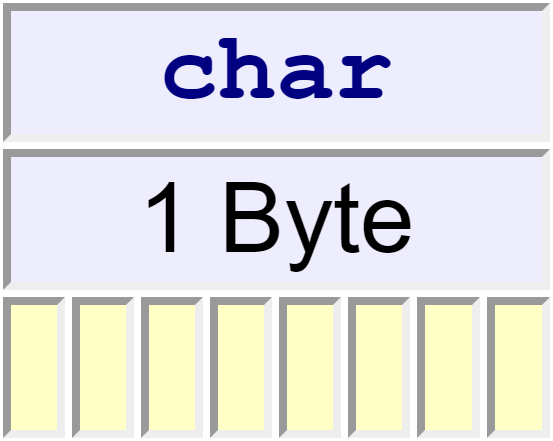
The basic source-code character set consists of 96 characters:
- space
- control characters
- horizontal tab (
'\t') - vertical tab (
'\v') - form feed (
'\f') - new-line (
'\n')
- horizontal tab (
- lower case letters:
athroughz - upper case letters:
AthroughZ - digits:
0123456789 - other:
_{}[]#()<>%:;.?*+-/^&|~!=,\"'
The basic execution character set consists of these characters plus the following control characters
- null character - all bits set to 0 (
'\0') - alarm (
'\a') - backspace (
'\b') - carriage-return (
'\r')
The char type represents Unicode characters using the 8-bit Unicode Transmission Format (UTF-8).
Locales
C++17 uses locale objects for international portability. A locale identifies the culture-specific set of features.
wchar_t
The wchar_t type is a wide character type that can store all the members of the largest character set among the supported locales. The wchar_t type has the same amount of memory and signedness as one of the other integral types. The integral type associated with the wchar_t type is called its underlying type.
We define a literal of wchar_t type using the prefix L followed by the value in single quotes around character, octal, or hexadecimal notation:
wchar_t k, m, n, p;
k = L'['; // character - note the leading L
m = L'\133'; // octal - note the leading L'\
n = L'\x5b'; // hexadecimal - note the leading L'\x
p = L'\X5B'; // hexadecimal - note the leading L'\X
The single quotes identify a character literal. The host platform converts this literal to its decimal value using the platform's encoding sequence.
char16_t
The char16_t type is a character type for representing characters using UTF-16. UTF-16 is an encoding sequence that can hold 1,112,064 code points from 0 to 0x10FFFF. This format is variable-length using one or two 16-bit code units; that is, it requires 16 or 32 bits to encode a character. 16 bits covers most of the Latin alphabets. This format treats characters outside the Basic Multilingual Plane as a special case. The Basic Multilingual Plane is the first group of continuous code points in Unicode, which contains the most commonly used characters.
The char16_t type uses the same amount of memory and signedness as one of the other integral types. The integral type associated with the char16_t type is called its underlying type.
We define a literal of char16_t type using the prefix u (lower case only) followed by single quotes around character, octal, or hexadecimal notation:
char16_t k, m, n, p;
k = u'['; // character - note the leading u
m = u'\133'; // octal - note the leading u'\
n = u'\x5b'; // hexadecimal - note the leading u'\x
p = u'\X5B'; // hexadecimal - note the leading u'\X
char32_t
The char32_t type is a character type for representing characters using UTF-32. UTF-32 is a fixed-length character encoding that can hold code points from 0 to 0x7FFFFFFF.
This type has the same amount of memory and signedness as one of the other integral types. The integral type associated with the char32_t type is called its underlying type.
We define a literal of char32_t type using the prefix U (upper case only) followed by single quotes around character, octal, or hexadecimal notation:
char32_t k, m, n, p;
k = U'['; // character - note the leading U
m = U'\133'; // octal - note the leading U'\
n = U'\x5b'; // hexadecimal - note the leading U'\x
p = U'\X5B'; // hexadecimal - note the leading U'\X
Floating-Point Types
C++17 defines three fundamental types for storing floating-point values:
float- a single-precision floating-point numberdouble- a double-precision floating-point numberlong double- a double-precision floating-point number, possibly with extra precision
C++17 does not specify the sizes of the float, double or long double type. The standard leaves them open to the host's implementation.
A double type provides at least as much precision as a float type. A long double type provides at least as much precision as a double type. The set of values of float type are a subset of the values of double type. The set of values of double type are a subset of the values of long double type.
The three floating-point types store values approximately. The most popular implementation is the IEEE (Eye-triple-E for the Institute of Electrical and Electronics Engineers) Standard 754 for Binary and Floating-Point Arithmetic (Wikipedia).
float
A float type typically occupies 4 bytes of memory:

Data Representation
Under IEEE 754, a float type occupies 32 bits, has one sign bit, a 23-bit mantissa and an 8-bit exponent. The arrangement of the mantissa and exponent bits is open:
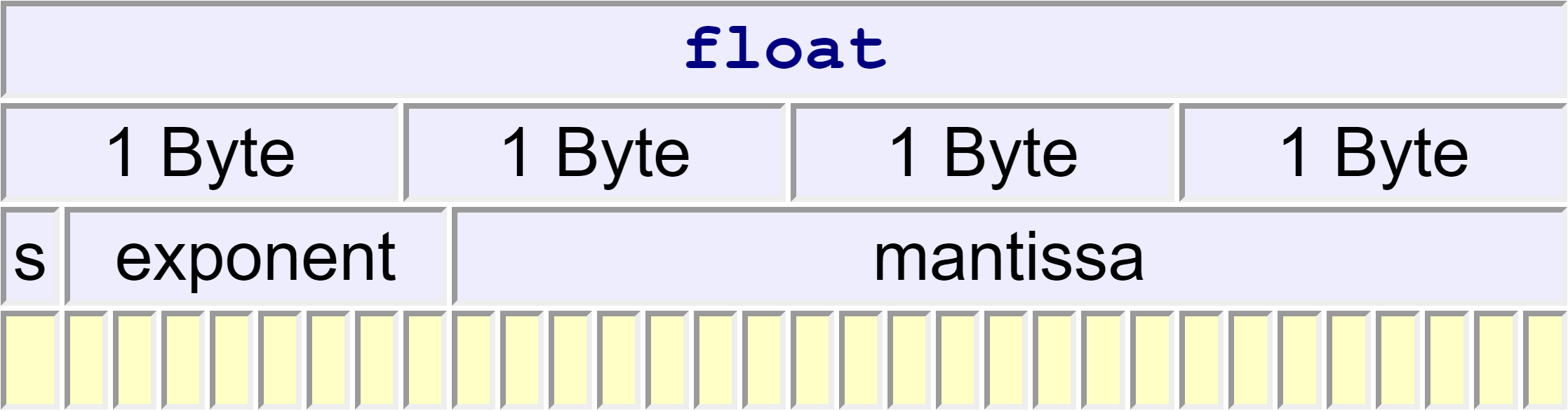
or
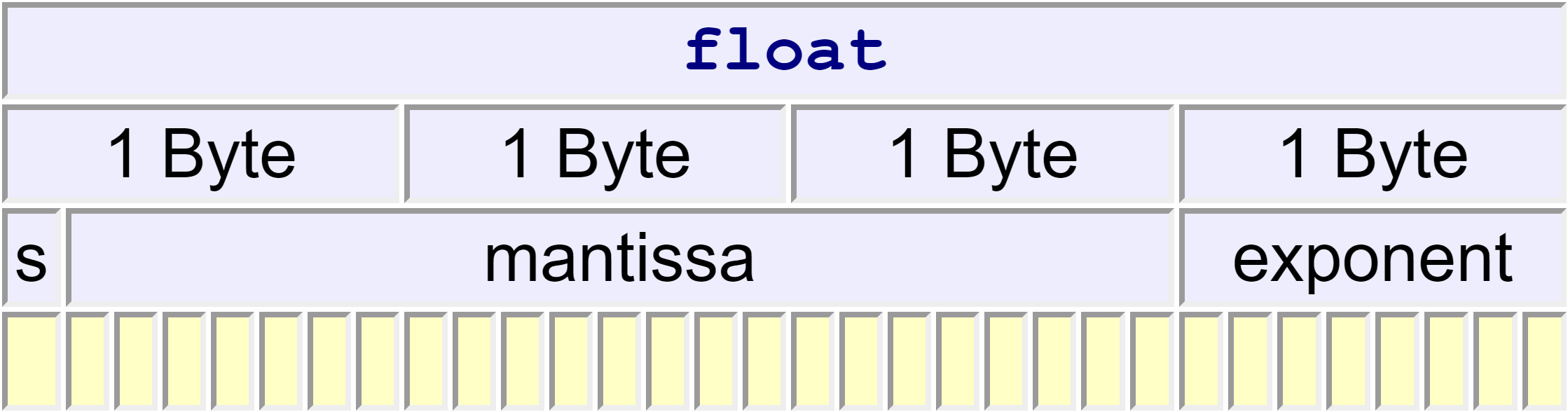
Under IEEE 754, the following formula determines the value stored
where is the value of bit () of the mantissa and is the exponent, which has a value between -127 and 128 inclusive.
Limits and Ranges
The limits on the number of significant digits and the ranges of the exponents for an IEEE 754 float type are:
| Type | Size | Significant Digits | Min Exponent | Max Exponent |
|---|---|---|---|---|
float | 4 bytes | 6 | -37 | 38 |
The exponent values in this table are decimal (base 10).
double
A double type typically occupies 8 bytes of memory:

Data Representation
Under IEEE 754, a double type occupies 64 bits, has one sign bit, a 52-bit mantissa and an 11-bit exponent. The arrangement of the mantissa and exponent bits is open:

or

Under IEEE 754, the following formula determines the value stored
where is the value of bit () of the mantissa and is the exponent, which has a value between -1022 and 1023 inclusive.
Limits and Ranges
The limits on the number of significant digits and the ranges of the exponents for an IEEE 754 double type are:
| Type | Size | Significant Digits | Min Exponent | Max Exponent |
|---|---|---|---|---|
double | 8 bytes | 15 | -307 | 308 |
The exponent values in this table are decimal (base 10).
long double
A long double type provides the maximum number of significant digits. A long double type typically occupies at least 8 bytes of memory:

void Type
The void type is an incomplete type. A type is incomplete if it is missing some information. C++ does not allow the creation of objects of type void.
We use a void type for the return type of functions that do not return a value and for generic pointers described in the next chapter.
Initialization
We can initialize a variable at its declaration in several different ways as shown below:
- by copying the initial value using the assignment operator on the same type (C-style)
- by copying the initial value using the assignment operator on a different type (C-style narrowing/promotion)
- by appending the braces-enclosed value to the declaration (direct-list initialization type-safe universal form)
- by equating the declaration to a braces-enclosed value (copy-list initialization universal form)
For example:
// Initialization Expressions
// initializer.cpp
#include <iostream>
int main ()
{
int n0 = 7; // C-style
int n1 = 7.2; // C-style - narrowing (loss of information)
int n2 {6}; // universal form braces-enclosed list
int n3 = {5}; // = is redundant
std::cout << "n0 = " << n0 << std::endl;
std::cout << "n1 = " << n1 << std::endl;
std::cout << "n2 = " << n2 << std::endl;
std::cout << "n3 = " << n3 << std::endl;
}
outputs the following:
n0 = 7
n1 = 7
n2 = 6
n3 = 5
The universal form is recommended. It checks the type of the value against the declared type and reports an error in the case of any mismatch. Since this form does not admit a narrowing of information, it is type-safe.
Type Inference
A compiler can infer the type of an object from a previously declared object. For instance, it can infer the type from the right operand of an initializer expression. In C++, the keyword auto specifies type inference.
In the following program, the compiler infers the type of n and i from the type of the initial value (6 and 0):
// Type Inference
// auto.cpp
#include <iostream>
int main ()
{
int a[] {1, 2, 3, 4, 5, 6};
const auto n = 6;
for (auto i = 0; i < n; i++)
std::cout << a[i] << ' ';
std::cout << std::endl;
}
and outputs the following:
1 2 3 4 5 6
Note that auto cannot appear in the top-level declaration of an array type. That is, we cannot write:
// Type Inference
// auto-compilation-error.cpp
#include <iostream>
int main ()
{
auto a[] {1, 2, 3, 4, 5, 6}; // ERROR
const auto n = 6;
for (auto i = 0; i < n; i++)
std::cout << a[i] << ' ';
std::cout << std::endl;
}
Type Alignment
C++ types can be aligned in memory at different spacings.
The alignof() operator returns the alignment requirement of its argument type. The following program
// Alignment of a Type
// alignment.cpp
#include <iostream>
int main ()
{
std::cout << alignof(int) << std::endl;
std::cout << alignof(double) << std::endl;
}
outputs
4
8
An alignment requirement represents the number of bytes between successive addresses of objects of a given type. Every object type has an alignment requirement. We can specify the alignment of an object type using alignas().
In the following program, the alignment of A is 4, because the member int n needs to be allocated on a 4-byte boundary. However, the alignment of B is 16, because we have specified that aligned alignas(16), where 16 is an integral multiple of an 8-byte boundary.
// Type Alignment
// align.cpp
#include <iostream>
// A is allocated at 4-byte boundaries
struct A
{
int n; // size 4 alignment 4
char c; // size 1 alignment 1
}; // size 8 alignment 4
// B is allocated at 16-byte boundaries
struct alignas(16) B
{
int n; // size 4 alignment 4
char c; // size 1 alignment 1
}; // size 8 alignment 16
int main()
{
A a[] {1, 'a', 2, 'b', 3, 'c'};
std::cout << "align of A = "
<< alignof(A) << std::endl;
for (int i = 0; i < 3; ++i)
{
std::cout << &a[i] << ": "
<< a[i].n << ", " << a[i].c << std::endl;
}
B b[] {1, 'a', 2, 'b', 3, 'c'};
std::cout << "align of B = "
<< alignof(B) << std::endl;
for (int i = 0; i < 3; ++i)
{
std::cout << &b[i] << ": "
<< b[i].n << ", " << b[i].c << std::endl;
}
}
The program above produces the output (the addresses will different in each execution):
align of A = 4
00BDFC24: 1, a
00BDFC2C: 2, b
00BDFC34: 3, c
align of B = 16
00BDFBF0: 1, a
00BDFC00: 2, b
00BDFC10: 3, c
Exercises
- Read C++ Reference on Fundamental Types